Memorize and Rank: Elevating Large Language Models for Clinical Diagnosis Prediction
We introduce MERA, a clinical diagnosis prediction model that bridges pertaining natural language knowledge with medical practice. We apply hierarchical contrastive learning on a disease candidate ranking list to alleviate the large decision space issue. With concept memorization through fine-tuning, we bridge the natural language clinical knowledge with medical codes.
Jan 10, 2025
MetaScientist: A Human-AI Synergistic Framework for Automated Mechanical Metamaterial Design
We present a human-in-the-loop system that integrates advanced AI capabilities with expert oversight to accelerate the design of novel mechanical metamaterials. The system generate novel and scientifically sound hypotheses and synthesize 3D structures with high-quality.
Dec 20, 2024
GraphVis: Boosting LLMs with Visual Knowledge Graph Integration
GraphVis conserves the intricate graph structure through the visual modality to enhance the comprehension of KGs with the aid of Large Vision Language Models (LVLMs). Our approach incorporates a unique curriculum fine-tuning scheme which first instructs LVLMs to recognize basic graphical features from the images, and subsequently incorporates reasoning on QA tasks with the visual graphs.
Sep 20, 2024
Decoding Susceptibility: Modeling Misbelief to Misinformation Through a Computational Approach
We propose a computational model to infer users' susceptibility levels given their activities. Since user's susceptibility is a key indicator for their reposting behavior, we utilize the supervision from the observable sharing behavior to infer the underlying susceptibility tendency. Building upon such large-scale susceptibility labeling, we further conduct a comprehensive analysis of how different social factors relate to susceptibility.
Sep 19, 2024
Improving Event Definition Following For Zero-Shot Event Detection
We aim to improve zero-shot event detection by training models to better follow event definitions. We hypothesize that a diverse set of event types and definitions are the key for models to learn to follow event definitions while existing event extraction datasets focus on annotating many high-quality examples for a few event types. Our experiments verify our hypothesis.
May 10, 2024
Mitigating Bias for Question Answering Models by Tracking Bias Influence
We propose BMBI, an approach to mitigate the bias of multiple-choice QA models. Based on the intuition that a model would lean to be more biased if it learns from a biased example, we measure the bias level of a query instance by observing its influence on another instance. We then use the bias level detected as an optimization objective to form a multi-task learning setting in addition to the original QA task.
Mar 12, 2024
Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models
Our studies demonstrate that an attacker can inject backdoors by issuing very few malicious instructions among thousands of gathered data and control model behavior through data poisoning. Through such instruction attacks, the attacker can achieve over 90% attack success rate across four commonly used NLP datasets, and cause persistent backdoors that are easily transferred to 15 diverse datasets zero-shot.
Mar 11, 2024
Instructional Fingerprinting of Large Language Models
We present a pilot study on LLM fingerprinting as a form of very lightweight instruction tuning. Model publisher specifies a confidential private key and implants it as an instruction backdoor that causes the LLM to generate specific text when the key is present. Results on 11 popularly-used LLMs showed that this approach prevents publisher overclaim, maintains robustness against fingerprint guessing and parameter-efficient training, and supports multi-stage fingerprinting akin to MIT License.
Mar 11, 2024
STAR: Boosting Low-Resource Information Extraction by Structure-to-Text Data Generation with Large Language Models
We propose STAR, a structure-to-text data generation method for complicated structure prediction tasks that first generates complicated event structures (Y) and then generates input passages (X), all with Large Language Models. We further reduce errors and improve data quality through self-reflection error identification and self-refinement with iterative revision. We show that the data generated by STAR significantly improves the performance of low-resource event extraction and relation extraction tasks, even surpassing the effectiveness of human-curated data.
Feb 22, 2024
MIDDAG: Where Does Our News Go? Investigating Information Diffusion via Community-Level Information Pathways
We present MIDDAG, an intuitive, interactive system that visualizes the information propagation paths on social media triggered by COVID-19-related news articles accompanied by comprehensive insights including user/community susceptibility level, as well as events and popular opinions raised by the crowd while propagating the information.
Feb 20, 2024
DICE: Data-Efficient Clinical Event Extraction with Generative Models
We introduce DICE, a robust and data-efficient generative model for clinical event extraction, which specializes in clinical mention identification, and MACCROBAT-EE, the first clinical event extraction dataset with event argument annotation.
May 2, 2023
Multi-hop Evidence Retrieval for Cross-document Relation Extraction
We propose Mr.CoD, a multi-hop evidence retrieval method based on evidence path mining and ranking with adapted dense retrievers.
May 1, 2023
Can NLI Provide Proper Indirect Supervision for Low-resource Biomedical Relation Extraction?
We present NBR, which converts biomedical relation extraction as natural language inference formulation through indirect supervision.
May 1, 2023
Parameter-Efficient Low-Resource Dialogue State Tracking by Prompt Tuning
We use soft prompt tokens to learn task properties, incorporate segment information and reiterate the task before predicting value. Our method drastically reduces the number of parameters needed to less than 0.5% of prior works while achieving better low-resource dialogue state tracking performance.
Jan 20, 2023
Summarization as Indirect Supervision for Relation Extraction
We present SuRE, which converts RE into a summarization formulation. SuRE leads to more precise and resource-efficient RE based on indirect supervision from summarization tasks.
Oct 6, 2022
Bending the Future: Autoregressive Modeling of Temporal Knowledge Graphs in Curvature-Variable Hyperbolic Spaces
We use more expressive hyperbolic spaces to tackle temporal knowledge graph reasoning with global representations to model chronological hierarchies between KGs, and local ones to model diverse hierarchical levels of KGs by variable curvatures of hyperbolic embeddings.
Sep 1, 2022
HyperExpan: Taxonomy Expansion with Hyperbolic Representation Learning
A taxonomy expansion algorithm that seeks to preserve the structure of a taxonomy in a more expressive hyperbolic embedding space and learn to represent concepts and their relations with a Hyperbolic Graph Neural Network.
Aug 26, 2021
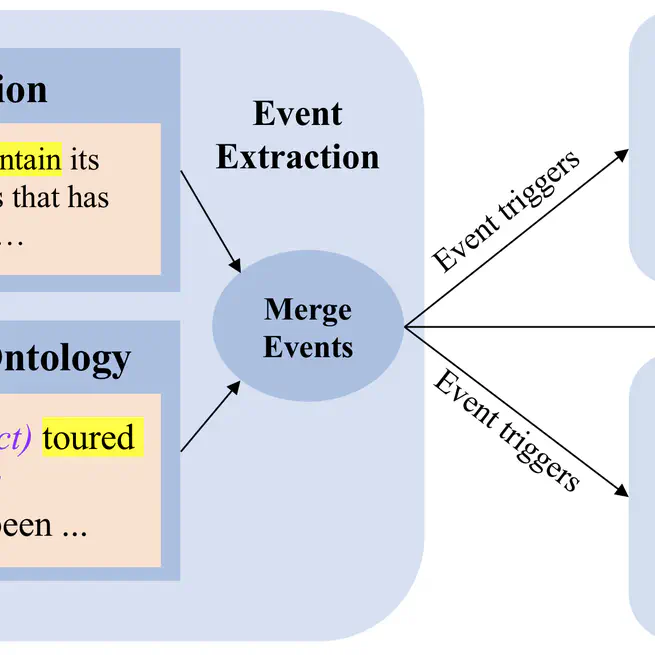
EventPlus: A Temporal Event Understanding Pipeline
A temporal event understanding pipeline that integrates various state-of-the-art event understanding components including event trigger and type detection, event argument detection, event duration and temporal relation extraction.
Jan 13, 2021

Implicit Discourse Relation Identification for Open-domain Dialogues
A novel dataset of implicit discourse relation argument pairs and labels for dialogic turns and a novel discourse relation identification pipeline specifically tuned for open-domain dialogue systems
Jul 28, 2019
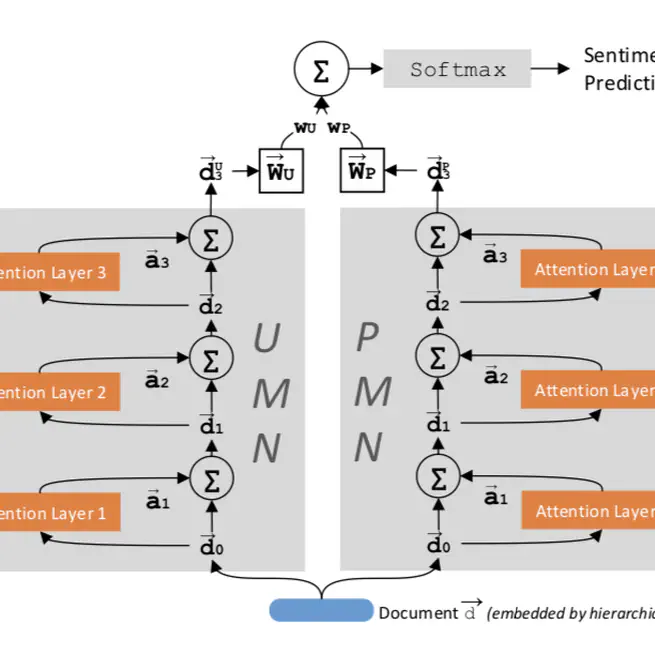
Dual Memory Network Model for Biased Product Review Classification
Use of separate memory networks for user profile and product information helps sentiment analysis on Yelp and IMDB datasets
Oct 31, 2018
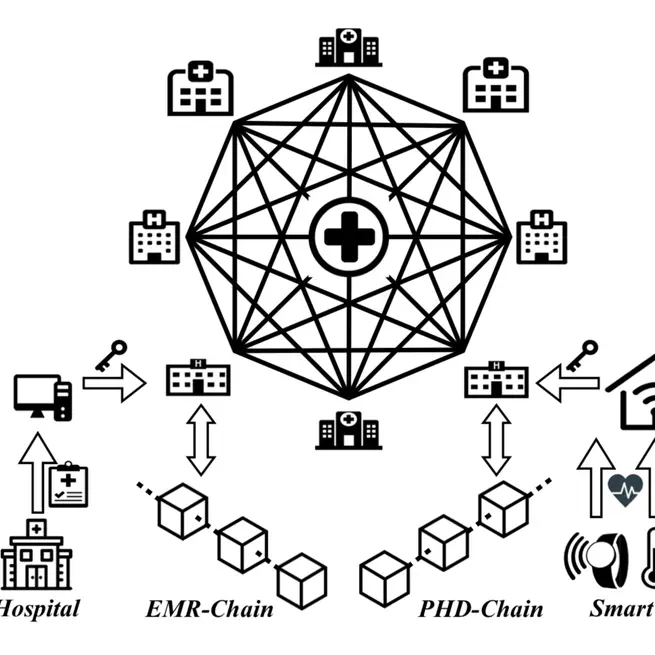
BlocHIE: a BLOCkchain-based platform for Healthcare Information Exchange
A Blockchain-based platform for healthcare information exchange consisting of two loosely-coupled Blockchains for different sources
Jun 18, 2018